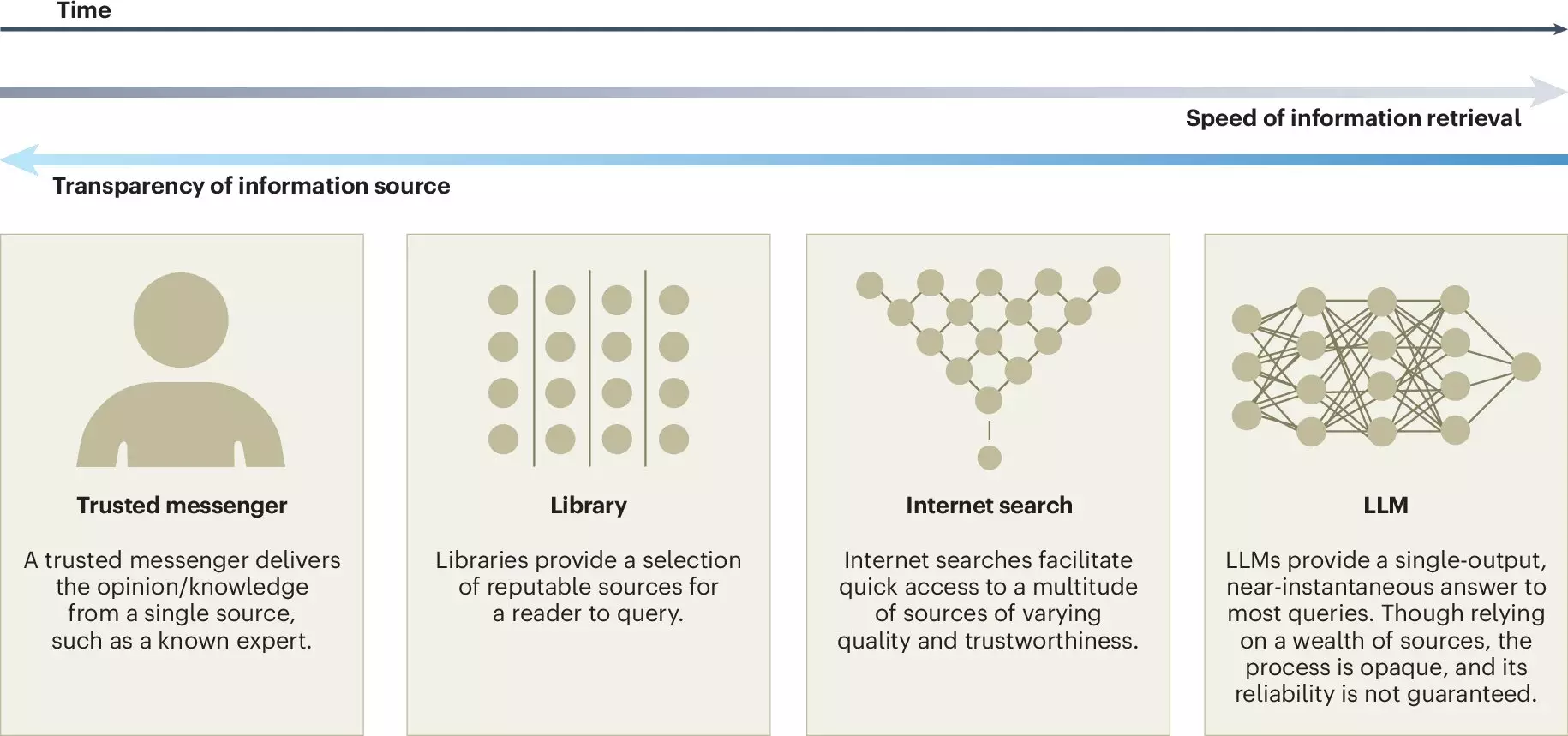
In recent times, the advancements in artificial intelligence (AI), particularly large language models (LLMs), have surged, integrating themselves into various facets of daily life. These models, such as ChatGPT, have not only transformed the way information is processed and generated but have also stimulated discussions among various fields regarding their implications on decision-making and collective problem-solving. A new investigation orchestrated by experts from Copenhagen Business School and the Max Planck Institute for Human Development offers a thorough examination of how these models impact collective intelligence, presenting both opportunities and challenges for collaboration and information sharing.
Collective intelligence refers to the shared or group intelligence that emerges from the collaboration and collective efforts of individuals. It is a dynamic process that leverages diverse knowledge and skills, allowing groups—whether small teams in corporate environments or extensive global networks like Wikipedia—to tackle complex issues and reach solutions that no single participant could achieve independently. In this context, LLMs can serve as valuable companions, assisting in synthesizing information, promoting discussion, and fostering comprehension among diverse groups with varied expertise.
The researchers advocate for several advantageous aspects of integrating LLMs into collective intelligence frameworks. One prominent benefit is the accessibility that these models offer. By providing inclusive translation services and writing assistance, LLMs democratize participation in discussions, enabling voices from diverse backgrounds to contribute effectively. This inclusion can yield richer dialogues and innovations as varied viewpoints surface and interweave.
Additionally, LLMs can significantly enhance productivity in brainstorming and opinion-forming processes. Capable of summarizing vast amounts of information and evaluating differing perspectives with ease, these AI systems help teams to expedite decision-making and find common ground faster. According to Ralph Hertwig, co-author of the study, balancing the potential benefits of LLMs while mitigating associated risks is essential as these systems become increasingly influential in shaping our decision-making environments.
However, accompany these benefits are substantial risks that warrant critical analysis. As reliance on LLMs increases, there could be a deterioration of intrinsic motivation among individuals to contribute to knowledge-sharing platforms like Wikipedia or Stack Overflow. The potential of proprietary models dominating the landscape poses a threat to the diversity and openness of shared knowledge, which are foundational to collective intelligence.
Moreover, the possibility of “false consensus” presents a notable concern. Individuals may inadvertently reach misguided conclusions, believing that there is widespread agreement on an issue based on LLM-generated outputs. Misrepresentation of minority viewpoints could further exacerbate this issue, with Jason Burton, a key study author, highlighting that such a disparity can lead to marginalization of essential perspectives and create an illusory consensus about social norms.
Recognizing these challenges, the authors of the article call for heightened transparency in the development of LLMs. Recommendations include a commitment to disclose the sources of training data and subjecting LLM development to external auditing processes. Such measures aim to cultivate a more profound understanding of how LLMs evolve while promoting accountability and ethical practices in AI development.
In addition to transparency, the study offers insights into the importance of including diverse representation in training datasets. It underscores the necessity of defining shared values and goals that prioritize inclusivity in the training processes, ensuring that the knowledge generated by LLMs reflects a balanced viewpoint.
Finally, the research underscores the need for ongoing discourse about the implications of LLMs on collective intelligence. By proactively considering the shifting online information landscape, stakeholders can anticipate both beneficial and adverse developments. This dialogue should encompass numerous pressing questions, such as how to prevent the homogenization of knowledge and the means by which credit and accountability should be allocated when collaborating with LLMs.
The intersection of AI and collective intelligence heralds a new chapter in human collaboration. To adapt effectively to this evolving dynamic, both researchers and policymakers must remain vigilant and innovative in rethinking the frameworks that govern our interactions with technology. With proper guidance, LLMs can enhance our collective capabilities rather than diminish them, driving us toward a more informed and collaborative future.