Deep learning has made remarkable strides in various fields by leveraging large datasets for model training. However, one persistent challenge that researchers face is label noise. Label noise occurs when the labels of training data are incorrect or misleading, leading to decreased accuracy during the model’s evaluation on test datasets. As models are trained and refined using these flawed datasets, their overall performance diminishes, making it imperative for scientists to develop strategies that address this critical issue effectively.
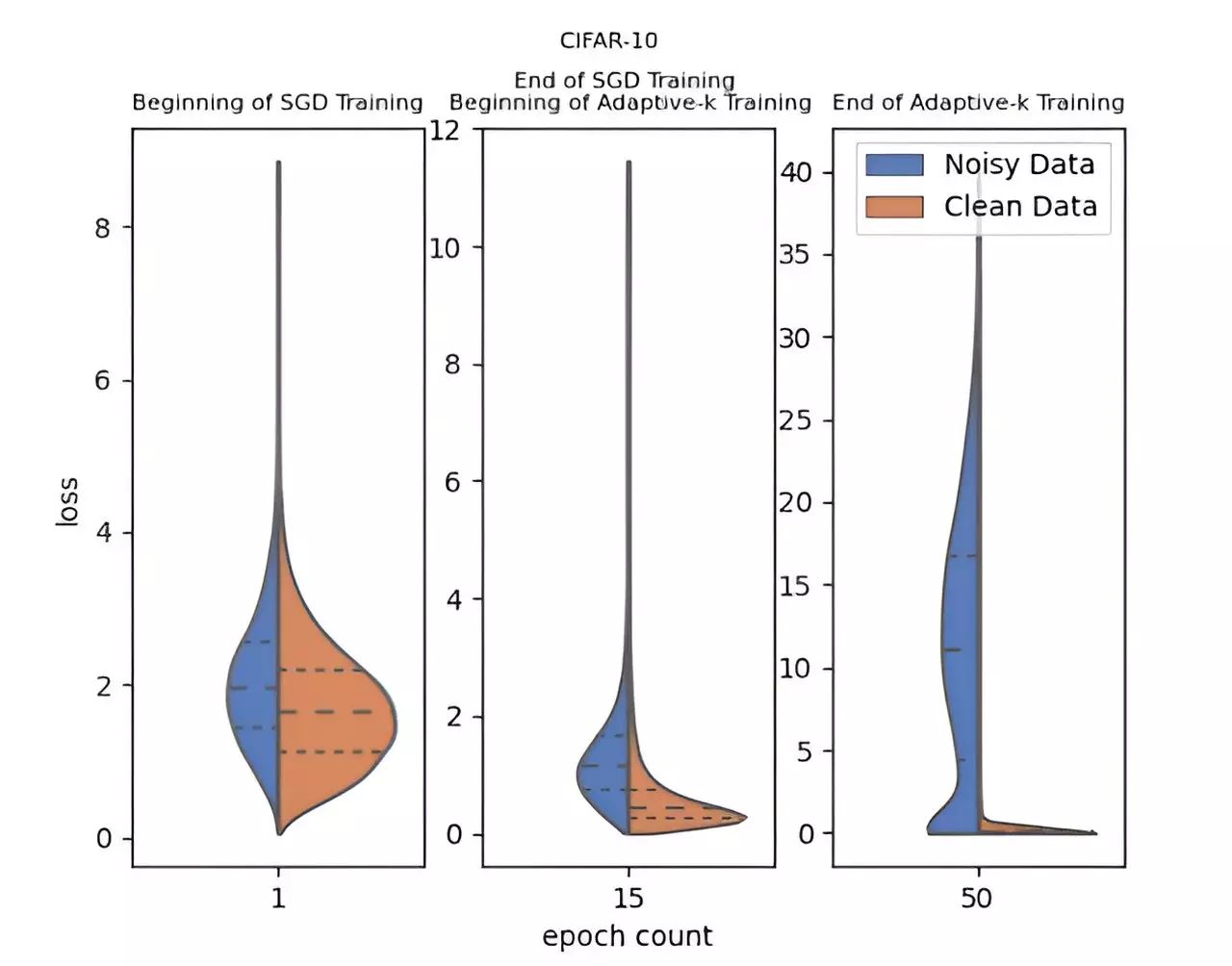
In response to the complications posed by label noise, a research team from Yildiz Technical University, led by Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali, has pioneered a novel methodology known as Adaptive-k. This approach reportedly enhances the optimization process, specifically targeting improvements in environments plagued by label noise. The remarkable aspect of Adaptive-k lies in its adaptive nature, which dynamically selects the number of samples to update from the mini-batch, facilitating a more refined differentiation between clean and noisy samples.
The significance of the Adaptive-k method is amplified through empirical studies that pit it against popular noise-handling algorithms, including Vanilla, MKL, Vanilla-MKL, and Trimloss. By contrasting its effectiveness with an Oracle scenario, where noisy labels can be perfectly identified and removed, the method reveals its aptitude in maintaining performance integrity in label-noisy datasets. The findings from experiments across three distinct image datasets and four text datasets affirm that Adaptive-k consistently outperforms its counterparts, showcasing its reliability and robustness.
One of the primary advantages of the Adaptive-k framework is its simplicity and ease of implementation; it requires no additional model training or data manipulation, making it highly efficient for practitioners. It operates effectively without necessitating prior knowledge of the dataset’s noise ratio, alleviating the burden on data scientists and practitioners who typically need detailed insights into their data. Furthermore, Adaptive-k shows compatibility with various optimization algorithms, including Stochastic Gradient Descent (SGD), SGD with momentum (SGDM), and Adam, further broadening its applicability across diverse settings.
The groundbreaking work surrounding the Adaptive-k method marks a substantial contribution to the field of deep learning, particularly in mitigating the adverse effects of label noise. However, the pursuit of improvement is never-ending. Future research endeavors will strive to refine this innovative method, examine additional applications, and enhance performance efficacy further. With ongoing exploration, the Adaptive-k technique has the potential to redefine how deep learning practitioners confront label noise, resulting in more reliable and accurate models across various domains. As deep learning continues to evolve, the Adaptive-k approach stands out as a promising solution to an age-old problem.